Hi folks. Today I’d like to start blogging about a personal project I’ve been working on for many months: building a copilot, an AI coding assistant. The goal is an assistant that initially targets Delphi, but could be expanded to many other languages. It’s tentatively named The Owl.
Contents
Today we’ll go on a journey through:
- the Owl’s architecture,
- talking to AIs via REST (briefly),
- then looking at Python async IO, generators and coroutines and how these are used in a web server to send the initial ‘hello’ message to the Owl’s chat frontend.
This will be the first post of… many.
It is important to note that this is being developed completely independently of Embarcadero / Idera. I do not manage, nor can comment on, any known or unknown AI strategy or product within Embarcadero. This is a personal, and very separate, project. Many people at Idera are aware I have been building it since it started, of course.
Why?
When I code in non-Delphi IDEs, I find having a coding assistant incredibly useful. I ask it questions, and rely on completions. It’s rapidly become an almost indispensible coding tool. It’s like syntax highlighting or code completion.
But neither Delphi nor C++Builder have one available.
This was a challenge to myself at the start of the year. I saw various AI coding assistants appearing. How did they work? Could I write one?
And I think I’m on the way to Yes. It’s not shipping yet. I’m not guaranteeing I will ship. But it’s time to blog about it.
Let’s dig in!
AI App Architecture
If you want to see code or interesting things about how AI send partial responses, skip to streaming or where it all comes together.
Roughly speaking, an AI can be easily communicated with via a REST API. So you don’t really need very much to get a chat / response in an app. You can get an AI in any software in a few minutes, under an hour if you’ve never done it before.
This article assumes you understand what REST is, and this blog doesn’t go into the detail of using OpenAI’s API (or any other) just yet. The focus is on architecture, digging into streaming, and showing how the first ‘hello’ message is sent to the client.
The Owl has a different design than simply a frontend communicating directly to an AI API.
Currently, the system is built of three layers:
- The Owl server: middleware. This bridges the AI (eg OpenAI, a local Ollama instance, etc) into what is actually a copilot, providing code assistant APIs as a REST interface. This is written in Python.
- IDE frontend: a thin client, as thin as possible to keep the actual product code mainly language-agnostic. This sits in the RAD Studio / Delphi IDE. Currently it provides a chat, plus multi-line code completion / prediction, and can be easily extended to provide other services like Explain or Document.
I myself mostly use code completion and chat interfaces when using any of the AI coding assistant products out there. - A local language client. This might be unexpected: surely, the IDE frontend and an AI/API server to talk to is all that’s needed right? And the IDE frontend can grab source code from the editor for context, and that’s all that’s needed, right? After all, that’s what Github Copilot does, so it’s enough, right?
Local Language Client
If a monologue on something not finished yet is not your thing, skip to streaming or where it all comes together :) There will be a much more interesting post in future digging into this service.
LLM AIs are not magic, and they thrive when provided information. I want a local system that fully understands your project’s source code in order to help the AI provide great answers. The goal is:
- If you’re using a variable, it should be able to look up the type definition to know what methods might be useful — and provide that info to the AI
- If you’re writing code using a class, it should be able to find related code and use that to suggest both what to write, and the way it’s written in your codebase already
- If you’re writing a unit test, it should be able to find code where the same class is used in practice, to write tests that capture existing behaviour
- Etc etc.
You get the idea: the core for the Owl is not the AI but a solid code understanding engine, which can provide valuable useful contextual information not just to the AI, but to you. A strong design principle for the Owl is, that the AI must be provided as much useful relevant information as possible. The local language client is what can provide that.
This has actually taken more time than the middleware and the frontend combined, and is slowly becoming a very powerful language tool. It’s the main bit that’s still being worked on, and may eventually be exposed as an LSP server with a number of custom JSON requests for custom data.
(It’s an intriguing idea if it can be expanded to provide code completion and other LSP functions, but right now the focus is on the AI tool’s needs: resolve types, give definitions, look up methods, etc.)
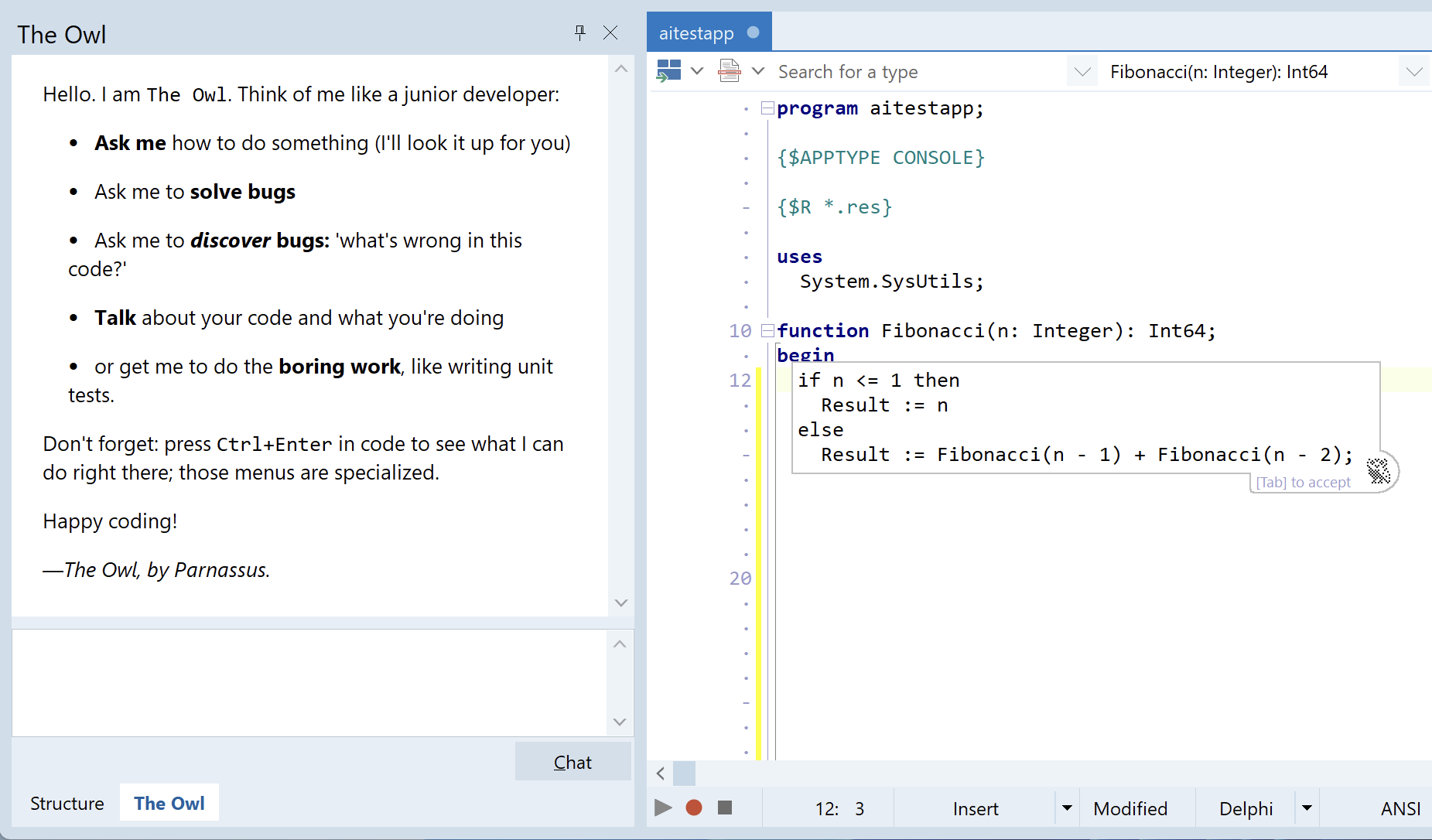
The chat, plus AI-powered code completion suggestions, have been complete (and working, and untouched without any more commits!) since March this year! Yes, that means some useful part of The Owl could have been shipped and used by you for months.
Shipping is important, but I have a good reason for this: the local language client is not finished yet. My client is not intended to be wrapper around an AI, only, but to be a genuinely in-depth language- and project-aware coding tool. So, it will ship when this part is ready.
So that’s the overall architecture. Today, let’s look at the first component: the Owl Server.
The Owl Server
OpenAI, along with local AI engines like Ollama – and for code security, I envisage this eventually being used with many people running local AIs on their own server, to keep all source code internal – all have quite similar APIs. Here’s OpenAI’s chat API, and chat is the main interface we’ll use, via strong prompting, to provide services like code completion.
The new assistants API may also be a good approach. Mistral has a completions API. The Owl’s middleware can wrap any and all of them, varying depending on the purposes of what it’s doing. For the purposes of this blog, let’s look at OpenAI.
Chat is a simple API sent to https://api.openai.com/v1/chat/completions, sending a JSON object containing:
- The model you want to use (eg GPT4o)
- The system message. Consider this as the identity of the AI: it tells it what it is, its purpose, generic information it needs to know, etc. When you create a ‘custom GPT’ in OpenAI’s website, you are effectively created a custom system prompt, just like this.
- The user message. This is equivalent to the chat message you write
- (Plus other things – you need to authenticate, etc. The Owl server uses the official OpenAI Python library.)
A chat has no memory. It’s a one-shot send-and-response. You send anything you want the AI to ‘remember’ as part of one of the messages the next time you call it.
All messages are tokenised by the AI. This is how it calculates the cost of each API call. We’ll get back to that later.
The result is a JSON object, which contains information such as the token count, but also a response string. It’s this response that is shown as the AI’s reply in a chat interface. (You might note that AI interfaces show this coming in word by word and we’ll get back to how this works later.)
This is very simple, and it’s trivial with either Delphi or Python to write code that calls this API with a JSON object and gets back the JSON response. Most if not all Delphi AI plugins I’ve heard of do this and call the AI provider directly, from the IDE or frontend.
So why not do the same? Write an IDE plugin that calls this or other similar APIs?
Aside: Why Insert a Server?
If a monologue on design is not your thing, skip to streaming or where it all comes together :)
Chat is the wrong API for an AI coding assistant. It is how you interact with an AI (in general: they are language models) but it forces the client to do all the logic that converts chat into useful assistant behaviour.
What a client wants is an API that provides chat (sure, for a chat window), but also an API that provides:
- line completion (where it suggests the rest of the current line of code)
- multi-line / block completion (where it suggests the rest of the block or method you might be writing)
- documentation
- unit tests, etc.
All these are different APIs, much more specific than a general chat that takes text info.
A documentation API, for example, will take the method or class that is being documented as parameters, and will likely have a different prompt – different instructions for the API – than one that completes the current line of code. It may also have a different backend implementation, which will change depending on the AI being interacted with. Mistral has a dedicated completions API.
Architecturally, this doesn’t belong in the frontend. A frontend should be a thin client.
Thus, the Owl’s server provides API endpoints for specific functionality. In fact, the very first endpoint it defined back on the very first day of coding was the /linecomplete endpoint.
Second, the APIs haven’t always been stable. OpenAI updated their API to version 1.0.0 a few months ago, and it was a breaking change. Handling that on the server backend is a single change for all users. Handling that in the frontend requires every single person using the Owl update their IDE plugin.
Third, the more than can be put on a server, the more that the code assistant product can be iterated and improved without you the user having to install a new version.
Fourth, it means there can be multiple clients in different IDEs, with very little logic in them. Most logic lives on the server. A frontend calls the server at appropriate times, such as via a chat UI or when the editor has an appropriate spot for completion, and handles responses, and that’s it. The Owl is not intended to be Delphi-IDE-only. Therefore the majority of the logic cannot live in the Delphi code frontend.
Thin client.
Potentially any IDE.
Update for all users, without requiring reinstalling the plugin.
Code assistant APIs and logic on your local computer.
AI backend (locally your own, or remote.)
Server Structure
The Owl is implemented in Python. Python is an amazing language for fast development and has an immense number of libraries.
If you don’t know Python, you’ll likely find the code snippets in this post easy to read, because like Pascal it’s a keyword-oriented, verbose, friendly language. The main thing is that indentation controls blocks. If a section of code is indented, that’s the same as having {-} or begin-end around it.
My setup: I chose Falcon as a lightweight, robust server framework. It’s lightweight and performant, but newer and not as widely used as Flask and FastAPI. I use Uvicorn on my home machine for testing, which is a standard Python web server it works with.
If you’re new to Python, I recommend:
- Using virtual environments (venv-s): these allow you to have multiple different sets of packages installed, and activate a specific set with specific versions for specific software you’re developing. That means you’re writing Foo, and you have the foo-env activated with bar-library 0.5 installed. When you work on your Zyzzygy app, you can have a different venv activated with bar-library version 0.4.
- Setting up a requirements.txt with the specific, or safe, package versions your software depends on
- Using type hinting. Really. Python code becomes unwieldy very fast when it grows and you don’t know what types you’re using. There is no runtime enforcement: this is for your editor only.
- Write tests. Python gives you runtime errors, not compiletime. The best way to solve Python problems is to have them caught automatically. I like the unittest library.
Side note: if you’re interested in partnering on the backend, the AI itself that provides answers, reach out. I’m interested in AIs that are finetuned per language, and would like to provide a specialised, fine-tuned for Delphi (and other languages in future!) AI that can be installed locally within a company’s private network.
Here is the second commit ever to the Owl’s server github repo, way back in January:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | from wsgiref.simple_server import make_server import falcon import completion app = falcon.App() # Routing line_completion = completion.LineCompletionResource() app.add_route(‘/linecomplete’, line_completion) if __name__ == ‘__main__’: with make_server(”, 41377, app) as httpd: # 41377 = hex A1A1, a pun on AI print(‘Serving on port 41377…’) # Serve until process is killed httpd.serve_forever() |
I love the simplicity of creating and assigning endpoints in Python web servers (and you can do similar things in, say, FastAPI.) I define a /linecomplete endpoint, and it will be handled by my LineCompletionResource object, which has methods that are called for GET and POST requests. It’s the assignment of endpoints to handlers I love, the app.add_route() call: it’s just so simple. I know this is common — all web frameworks have simple routing — but the text-based simplicity and clarity of this code is beautiful.
Each of the resource classes looks at the parameters that are sent to the endpoint, and returns a result. The classes allow different AI backends and stream results, and are reasonably complex.
However, even today, the core server file is not much more complex than the version above: it creates more endpoints, and provides a way for endpoints to be backed by different AI engines, and it changes from a WSGI server to an ASGI server, and it has error handling. But that’s about it.
WSGI-ASGI-what?
Streaming.
WSGI and ASGI are specifications for how Python web servers and web frameworks communicate / interact with each other. ASGI, which is less commonly supported, is asynchronous.
In my setup, Uvicorn is the web server, and Falcon is the web framework. The ‘app’ object above is a Falcon application. Falcon can work with any ASGI-compatible server because ASGI is an API or protocol.
To run a server, I start Uvicorn and tell it to load the Falcon app: uvicorn athena:app This starts the Uvicorn server, looks in the athena.py file, and runs the app.
If you’ve used any AI like ChatGPT, you’ll have seen the chat response come in word by word (token by token.) This is actually a single JSON object response, something like:
1 2 3 | { “response”: “Hello, I am `The Owl` and I am a Delphi coding assistant.” } |
(with many other fields: it might include JSON data for the token count, the response ‘role’, etc.)
So how is a single JSON object shown token by token?
It is not sent and processed as a whole JSON object. It is sent over the wire piece by piece, using Server Sent Events (SSE.)
If you watch an AI’s response come in, such as with curl, you will see something like the following being printed to the console:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | $ curl –v https://[the–owl–domain]/v1/hello < HTTP/2 200 < date: Sat, 20 Jul 2024 17:16:04 GMT < server: railway < content–type: text/event–stream < cache–control: no–cache < x–accel–buffering: no < data: { “response”: “ data: Hello. data: I data: am data: `The data: Owl`. |
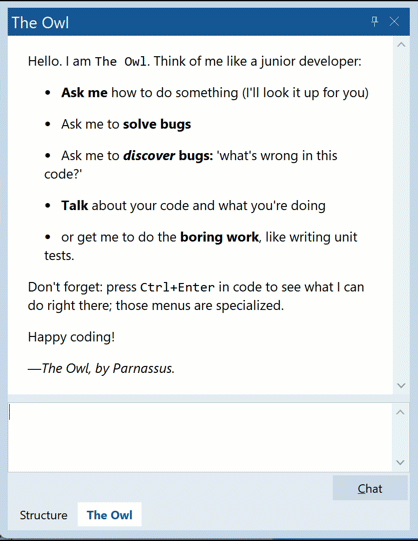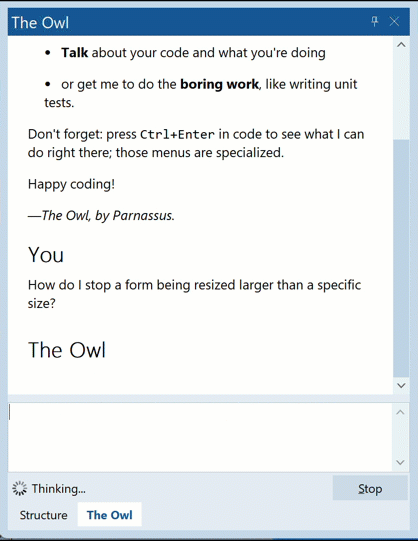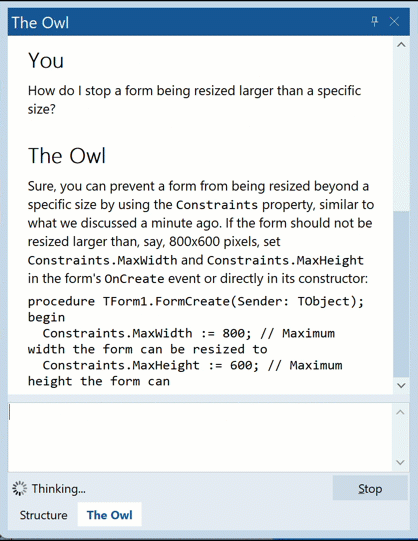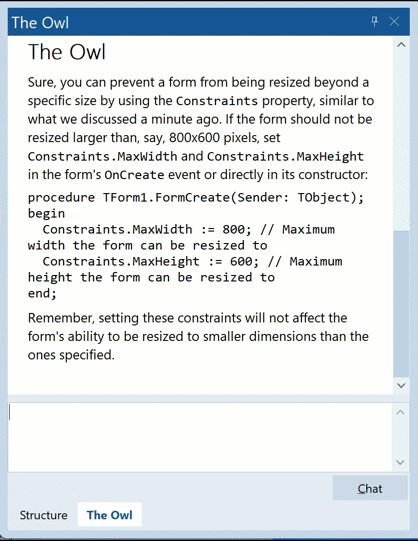
That is, ‘data:[space]’ with blank lines between, all of which come in separated by fractions of a second. Note the text/event-stream content type, and lack of caching shown in the response headers.
This is the SSE protocol: an incredibly simple protocol for sending responses piece by piece.
Most webservers cache responses, which causes issues because you want to send each of these SSE outputs immediately. Otherwise your AI response doesn’t come in token by token but all in one go. Although running Uvicorn locally worked fine, running through my PythonAnywhere account cached sending data even using their beta support for ASGI. For online testing, I switched to deploy on Railway, where SSE works fine.
Side note: PythonAnywhere is a great service for running Python code on a server. The support is great, they are very friendly and helpful, it’s quite cheap, and I used it extensively for testing a real-world server for a couple of months until the need for SSE made me find a host that supported it.
They’re a brilliant service: you basically get a Python-enabled server and can do almost anything. Check them out.
Streaming SSE in Python
The magic of coroutines.
I had not used Python’s coroutines or asyncio until I started writing the Owl server. But they are beautifully simple to use. And streaming SSE events is just a matter of creating a Python generator function which yields SSE items.
What does that mean?
Warning: I am not an expert on coroutines. I’ve learned through writing them. This is my best simple explanation.
A generator function is one that can keep on producing items, until it runs out. Instead of return-ing a value, you use the yield keyword instead. This turns any method into a generator method. The item you yield is ‘returned’ but the state of the method is retained, so it is able to continue execution.
Your code calling the generator iterates over the yielded values (much as though it was a container) because iteration as a concept abstracts from the source of the data.
Coroutines are introduced when you use asyncio. A coroutine is declared with the async keyword: async def Foo(). You can await a coroutine, and it will complete execution before returning. Or, a coroutine can temporarily yield control, such as when it yield-s a value. Its stack is retained so execution can resume in the coroutine, and execution is scheduled via the asyncio library. (There are multiple possible asyncio alternatives; I used uvloop for a while when developing the server.)
You can use asynchronous iterators via async for inside a coroutine.
Coroutines are excellent for lightweight asynchronous programming. They allow effectively non-blocking code – note they only give up execution at predefined points / keywords – meaning waiting on network or file IO, which can be slow, are excellent points to let execution do something else.
Where it all comes together: the Hello message
Let’s see both of these in practice, showing how the Owl chat ‘hello’ message is returned, in the Falcon framework. This is where it all comes together.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | class HelloResource: “””Simple ASGI async class to return a Hello message, the one displayed in-IDE the first time the window is displayed.””” async def on_get(self, req : Request, resp : Response): print(‘Hello: GET request received’) params = req.params print(f‘Params: {params}’) resp.content_type = ‘text/event-stream’ resp.set_header(‘Cache-Control’, ‘no-cache’) resp.set_header(‘Connection’, ‘keep-alive’) resp.set_header(‘X-Accel-Buffering’, ‘no’) # https://serverfault.com/a/801629 resp.sse = self._get_hello_message() |
This is the Hello resource handler. In the main app, it’s connected to the endpoint via:
1 2 | hello = hello.HelloResource() app.add_route(‘/v1/hello’, hello) |
The on_get method is an async method that the Falcon ASGI app will call when it gets a GET request to the /v1/hello endpoint. Here, for the sake of a demo, I print some diagnostics, the GET parameters. Then, set some headers for the response, and the key part: set the response SSE property to my hello message generator.
I have a small helper function, SSEventFromText, that creates a Falcon SSEvent from a string. The hello message generator looks like this:
1 2 3 4 5 6 | async def _get_hello_message(self): yield SSEventFromText(‘{ “response”: “‘) async for part in common.words_and_spaces_generator(prompts.athena_hello_message): await asyncio.sleep(0.02) yield SSEventFromText(part) yield SSEventFromText(‘”, “success” : “true” }’) |
This generator:
- Yields the start of a JSON string with a response field
- Itself calls a generator (more in a moment) yielding each value it generators
- Finishes by yielding the end of the JSON structure with a “success” value. This means you get a JSON string with a response and success fields.
So what’s the async for part?
The ‘hello’ message doesn’t actually come from an AI, because that would be a waste of resources. But AIs stream responses and their messages come in piece by piece, so the ‘hello’ message does the same. The text you see in the Chat window is a string (Markdown-formatted) stored in the prompts.py file. Instead of sending the entire multi-paragraph string, it splits it up into words, and sends it back one word at a time with a tiny 20ms delay between each one. This results in a fast stream of SSE tokens.
The words_and_spaces_generator is a slightly ugly function that splits the text by lines, then by words, and yields each one:
1 2 3 4 5 6 7 8 9 | async def words_and_spaces_generator(text): for line in text.split(‘\n’): #splitlines(): if line: # Only process non-empty lines for word in line.split(‘ ‘): if word: # Only yield non-empty words yield word + ‘ ‘ # this adds spaces back, when splitting at spaces yield ‘\n’ # this adds newlines back, when splitting at newlines else: # For empty lines, just yield a newline yield ‘\n’ |
Kindof ugly, but it was written for and works for the ‘hello’ message.
The end result is:
- The Falcon async GET response method assigns the SSE property to a generator, which the Falcon framework will iterate over to generate the SSE (streaming) response
- The generator yields parts of a JSON string: the prologue, then the message, then the epilogue
- For the message, the generator method itself calls another generator which yields the ‘hello’ message word by word
The POST version is very similar.
End result? Omitting all the frontend part letting Delphi handle streamed events and partial JSON, let alone formatting Markdown on the fly from partial Markdown strings, we get this:
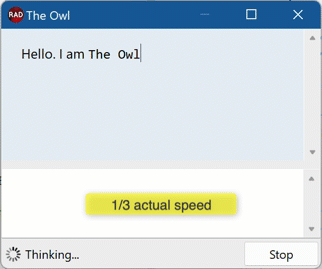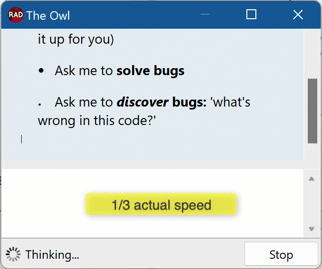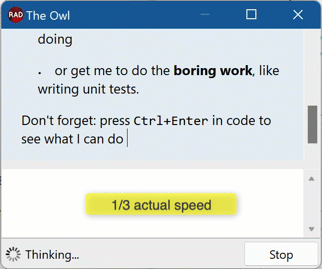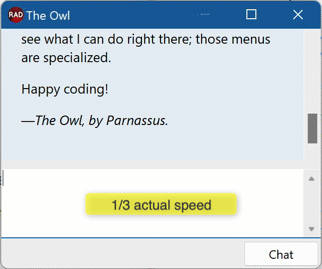
Next Up
There are some big missing pieces in this post. Some include:
- The Owl wraps different AIs, so it does not return the response an AI API sends back verbatim. (Yes, it still streams, which is where it gets complex.)
- How does the Delphi frontend handle all this? How does Delphi handle a streaming response like the above to display token by token? Delphi’s JSON libraries can only handle valid, complete JSON, but a streamed response is usually incomplete and invalid JSON.
- And, it’s formatted. How do you format Markdown on the fly from partially complete Markdown text arriving token by token?
Then there are more implementation questions:
- What about AI memory? So when I chat, it knows what we were talking about? Or when it completes, it might be inspired by what I asked it?
- What about details of implementing chat, line and block completion, documentation, unit test endpoints on the server?
- What about the details of the Delphi frontend in general: the ToolsAPI plugin, how it implements a chat window, how it implements completions?
- And – what was all that about a local client that parsed and understood source code?
There is a vast amount to dig into. This will take several blog posts. More in the next post!
Leave a Reply