Welcome back: we’re discussing how to write an AI coding / copilot service named The Owl. This is the post I have been most looking forward to writing, because it describes a logical but semi-crazy sequence of incremental streamed parsing layers.
At the end of Part 1, we had a Python server that streamed text to a client using Server Sent Events. In the client, this let us display text as it arrived word by word:
But if you look closely, this isn’t plain text: it’s formatted. In fact, it’s Markdown.
AIs can easily return Markdown-formatted text, but the server response from the AI server is not just the text but a complex object (ie, JSON.) Code reading the AI’s response needs to handle partially complete data, and process it as it arrives piece by piece.
But this is not the only layer of parsing and streaming on the fly. In fact, the Owl has four layers of parsing incomplete streams of data:
- The AI library returns a stream of data; this includes the actual AI response. The response grows as each token is returned, so it is parsed chunk by chunk
- That AI response is, at the same time as it arrives and is parsed, streamed to the client. That is, the incomplete response is wrapped in JSON, using fields specific to the Owl, and streamed token by token as each token is received from the server
- The client gets that JSON, and parses it as it arrives to also extract the AI response. At this stage the client has the streaming text of the AI… through a few layers.
- The AI response is Markdown-formatted. So this is parsed on the fly to provide rendering information using a formatting state machine that is updated with each token
This is four different levels of data arriving via a stream and being parsed and handled on the fly, token by token as it arrives. Of them all, the most complex to implement (to me) was the Markdown parsing.
If your client talks directly to an AI, step 2 is not required; you can go straight from the AI server to the client. And, there are Javascript libraries to present AI chats so you don’t need to implement any of this yourself. But if you’re writing your own middleware and client, you’ll need to handle some form of on-fly-fly parsing of incomplete data.
Besides, it’s fun!
Contents
Contents
This post will describe first, how an AI library is wrapped in the Owl’s server code, and then how all the above works in practice with code samples. It uses both Python and Delphi, but even if you don’t use one of those languages it may still be useful for you.
Wrapping an AI library
The Owl provides its own REST API but under the hood it can be implemented with multiple AI engines: currently, it supports OpenAI, Mistral, and Ollama. This has a pretty basic base class:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | class AICallBase: def _get_max_send_tokens(self) -> int: # Smaller for, eg, GPT-3.5 raise NotImplementedError() async def get_response_json(self, system_prompt : str, user_prompt : str, max_tokens : int): “””Get the full response from the AI, including headers and status code. This only returns when it has the full response. { “response”: “The response text”, “success” : “true | false”, error: “error message | blank” }””” raise NotImplementedError() async def get_response_json_sse(self, system_prompt : str, user_prompt : str, max_tokens : int): “””Get the response from the AI as a series of async yielded Server-Sent Events. { “response”: “The response text”, “success” : “true | false”, error: “error message | blank” }””” raise NotImplementedError() |
The APIs are implemented via get_response_json_sse(), because it streams. But it can be handy when coding to get the full response in one go, which is what get_response_json() is for. Get_response_json_sse() is a Python generator function, ie, will yield results as it is iterated, and this allows us to build and send the JSON string as tokens arrive from the AI.
The comments here describe the current format of the Owl’s JSON sent to the client: currently a series of simple key/value pairs for the response itself and some other data.
Let’s look at how this is done using OpenAI’s Python library.
Asynchronous OpenAI chat
This code is straight out of the library documentation:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | # Set the data messages = [ { ‘role’: ‘system’, ‘content’: system_prompt, }, { ‘role’: ‘user’, ‘content’: user_prompt, } ] client = AsyncOpenAI(base_url=base_url, api_key= ..., organization= ... response = await client.chat.completions.create(model=self._get_openai_model(), messages=messages, max_tokens=max_tokens, stream=True ) return response |
It creates an async chat completion (note you should use a secrets manager to avoid leaking your API key). This is iterable, and this is where the magic happens. Let’s implement an OpenAI descendant of the AICallBase class.
First, get the completion object per above, and check if it has an ok status code:
1 2 3 4 5 6 | async def get_response_json_sse(self, system_prompt : str, user_prompt : str, max_tokens : int): response = await self._get_response_internal(system_prompt, user_prompt, max_tokens) if response.response.status_code != 200: #raise Exception(f”Error: {response.response.status_code} {response.response.reason}”) yield SSEventFromText(‘{ “success” : “false”, “error”: “‘ + response.response.reason + ‘”‘) |
I return JSON with the error but for a while just raised an exception. SSEventFromText() is a tiny wrapper function to return a Falcon SSEvent from a string.
If there’s a failure, it returns a single event with JSON containing a failure flag and info on what the error was.
However, if all is ok, we can iterate over the chunks in the response. Remember, this is happening as the server streams the response to us:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | is_first = True # Iterate over the events in the response chunk : ChatCompletionChunk async for chunk in response: data_dict = chunk.model_dump() # json.loads(text_data) # Check if the necessary keys exist in the dictionary if ‘choices’ in data_dict and len(data_dict[‘choices’]) > 0 and ‘delta’ in data_dict[‘choices’][0] and ‘content’ in data_dict[‘choices’][0][‘delta’]: # Get the ‘choices[0].delta.content’ value content = data_dict[‘choices’][0][‘delta’][‘content’] if content is not None: if is_first: yield SSEventFromText(‘{ “response”: “‘) is_first = False # Yield the content yield SSEventFromText(content) else: # None at the end, ie done break yield SSEventFromText(‘”, “success” : “true”, “error”: “” ‘“ }\n‘) |
I tend to find loops with flags like ‘is_first’ to be a code smell, but honestly I can’t really find a better way to achieve this here.
The chat response can contain a number of responses: think of these as multiple replies. Since we didn’t call the AI asking for more than one, there’s a single choice of replies, thus the [0] index. Then we get the delta (what’s new, which will be one or more tokens that have arrived) and the content, which is the text of that delta.
Remember from our method documentation that we want to return JSON in the format:
1 2 3 4 5 | { “response”: “The response text”, “success” : “true | false”, “error”: “error message | blank” } |
Plus, our method is a generator: it will yield content. Thus, the first time it’s called we want to yield the start of the JSON (that’s the ugly ‘is_first’ flag). Then, we want to yield the AI’s response until that runs out; finally, yield the last of the JSON.
Using this generator for the web server
Remember part 1, where we used the Falcon web framework and wrote a Hello World generator to return text?
Simply use this generator instead:
1 | resp.sse = get_response_json_sse(system_prompt, user_prompt, max_tokens) |
Now you’re getting the AI server’s response piece by piece, and streaming it as JSON to your client.
Client-side
We’re implementing our client as a plugin for the Delphi IDE. While Delphi has excellent Python support, we’re going to use Delphi’s native HTTP components to communicate with the server. Last year (2023, version 12.0?) the HTTP components were updated to support SSE (streaming) responses, so we can give an object representing our request the latest chunks one by one as they come in:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | procedure TDataModuleREST.EventReceiveDataEx(const Sender: TObject; AContentLength, AReadCount: Int64; AChunk: Pointer; AChunkLength: Cardinal; var AAbort: Boolean); begin var AIReq := // the AI request object associated with this server response if AChunkLength <= 0 then Exit; // Convert the chunk (via Bytes) to a string assuming UTF-8 encoding var Bytes: TBytes; SetLength(Bytes, AChunkLength); Move(AChunk^, Bytes[0], AChunkLength); var ReceivedString := TEncoding.UTF8.GetString(Bytes); AIReq.AddChunk(ReceivedString); end; |
Delphi has multiple inbuilt JSON libraries, but all of them assume the JSON is valid and complete. We cannot use them to parse incomplete JSON that is arriving on the fly token by token. However, in order to display the AI’s response word by word as it comes in we want to parse the streaming partial JSON, which remember will be an incomplete or possibly complete string of the form:
1 2 3 4 5 | { “response”: “The response text”, “success” : “true | false”, “error”: “error message | blank” } |
to get the response as it arrives (error handling is out of scope for this blog post.) That response will be Markdown and is what we want to display.
Incremental JSON
JSON supports nested objects, but to keep this simple the Owl’s JSON that it returns — which we wrote above — is flat: it uses JSON as a series of key/value pairs.
We do not want to re-parse the JSON every time a new piece of text is added. Instead, we want to iteratively parse, to be as efficient as possible. This is in the TIncrementalJSONParser class.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | TIncrementalJSONValueEvent = procedure(const AKey, AWholeValue, AThisIncrement : string; AComplete: Boolean) of object; TIncrementalJsonParser = class private FBuffer: string; FCursor: Integer; FData: TDictionary<string, string>; FIsKeyComplete, FIsValueComplete: Boolean; FLastKey : string; FOnIncrementalValue: TIncrementalJSONValueEvent; // (Some internal methods here) public constructor Create; destructor Destroy; override; procedure AddChunk(const Chunk: string); property Data[Key : string] : string read GetData; property OnIncrementalValue : TIncrementalJSONValueEvent read FOnIncrementalValue write SetOnIncrementalValue; end; |
Each time a new piece of text comes in, it is added via AddChunk to the buffer, FBuffer. The text is sanitised from any SSE formatting before being appended to the buffer. It boils down to:
1 2 | FBuffer := FBuffer + Line; ParseBuffer; |
FCursor is a cursor into the buffer (effectively an index or pointer), which stores the point up to which we last successfully read, and each key/value pair is stored in the FData dictionary. ParseBuffer() does the work: it incrementally parses.
As a user of the class, you can always get the value for any key via the Data[] property, noting that the value might be incomplete, but perhaps more useful is the OnIncrementalValue event: this is fired every time a value is changed, as it changes. So if you have a long key/value pair like an AI response, you will get this event fired many times as each token arrives in the response, and the JSON string is parsed another word along.
Values are always strings.
How it works
Using JSON as a flat list of key/value pairs, rather than nested objects, makes this considerably simpler. Both the keys and values are strings surrounded by double quotation marks.
The internal ExtractString method starts at a position in the buffer, and scans for the next ” mark. From there, it scans until the second ” mark (handling escaped \” symbols), or hits the end of the buffer. It copies the string between those two points and returns it, along with a variable indicating if it found the ending ” or not. If not, we know the value is incomplete.
Using this, you can build a simple parser. It does re-read strings until the end of a string is found, but it’s still reasonably performant. Consider how the following JSON will be parsed:
1 | { “key” : “the value is here” } |
This will come in piece by piece, such as:
1 | { “key” |
It parses the open quote and then looks for a string with ExtractString. Here, it finds a complete one. Using the FIsKeyComplete and FIsValueComplete flags, we can track if we’re reading a key or value; here it will set FIsKeyComplete to true and move on to parsing the value, storing the current key for which it’s attempting to read a value in FLastKey.
But there is no value yet, so the FData dictionary contains an entry with “key” mapping to an empty string. FCursor is updated to the last point is successfully parsed, in this case the end of the string.
When more data comes in:
1 | { “key” : “the val |
It knows it has a complete key but incomplete value, so tries to read the string again via ExtractString. This time, it will get “the val” but will return that it is incomplete. FData is updated to map “key” to “the val”, the event is called to notify you, but FIsValueComplete is still false meaning next time a chunk comes in, it will try to read the value again.
More data comes in:
1 | { “key” : “the value is here” } |
FCursor is still pointing to the start of the value, because last time it read, the value was incomplete. This time, ExtractString finds the end quote, so it returns both the value and a flag that the value is complete. We know what key we’re parsing the value for via FLastKey, so the dictionary is updated, the event is fired, and state is reset to look for a key: FIsKeyComplete FIsValueComplete are both false, and FLastKey is “”.
Incremental Markdown
But we’re still not done. We’re parsed the incrementally arriving JSON to get the AI’s response, but that’s Markdown formatted text.
Now, you could just use a Markdown control and set the entire value to the text each time. While it would work, that kind of approach tends to lead to bugs like flicker, or making it impossible to select text (because it’s constantly being rewritten underneath the mouse), or impossible to scroll (when resetting the text it will often reset the scroll position.)
Besides, Delphi has no inbuilt Markdown renderer — the IDE uses a custom version of the one linked above, but it’s not exposed to plugin writers via the ToolsAPI. And a plugin can’t easily include its own version of a component that users might also have installed due to clashes: only one will be able to be loaded. There are workarounds, but each of them requires maintaining a customised version of the component (which is exactly what the IDE does.)
So we’re going to separate parsing from rendering, and either render by converting the Markdown to HTML or maybe RTF; either way, new content will simply be appended.
TMarkdownIncrementalParser
Markdown is considerably harder to parse than a simple flat key/value list of JSON pairs. It has nested state: you might have bold text, with some of that itself being italic (or a heading, with a few words marked as code in that heading.) Some of the markup symbols have duplicate meanings: an asterisk * can start an unordered list, or could be starting an italicised section or text, or can be part of ** to start a bold section of text.
1 2 3 | # Heading with `code` * Dot point with *italic **and bold** text* |
But because this is streamed, there is one assumption, which is that you can always figure out the state (eg, italic) before the text to which it applies. This means that this style of headings:
1 2 3 4 | Heading here ============ Text |
will not be supported. Only the form of headings where they are prefixed with hash marks # or ## will be parsed.
State and events
We’re going to parse markdown into a series of events. These are not Delphi events but are akin to instructions: enable bold, change colour to red, append text ‘hello’, etc. These can then be used to create HTML or rich text.
Nested state like the italic and bold above can be represented well, via a stack. The current formatting is the result of applying the entire stack: when something new is encountered, just push a new format onto the stack.
Each of these events has a start, content which is text, and an end. This corresponds to pushing and popping state on the stack, plus the text for which it applies.
We will support headings (of any level), incline code, code blocks (large multi-line pieces of code), and both unordered and numbered lists. This could be extended in future to support links or other formatting.
Then, we need to store the parser context; and have a buffer, cursor into that buffer (following the same idea as JSON: the cursor points to the last location that was successfully parsed) and a bit of other info, plus an event you can hook into in order to do the final HTML/etc generation. You get a class definition that starts like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | type TParserState = ( psNone, psHeading, psInlineCode, psCodeBlockStart, // State to handle the start of a code block psCodeBlock, // State when inside a code block psList ); TMarkdownEvent = (meNull, meStart, meContent, meEnd); TMarkdownElementType = (metNull, metText, metHeading, metInlineCode, metInlineBold, metInlineItalic, metCodeBlock, metNumberedList, metUnorderedList); TMarkdownCallback = procedure(ElementType: TMarkdownElementType; Event: TMarkdownEvent; const Text: string) of object; TMarkdownElementTypeHelper = record helper for TMarkdownElementType function IsInline : Boolean; end; TParserContext = record State: TParserState; ElementType: TMarkdownElementType; procedure Reset(AExpectedElement : TMarkdownElementType); end; TMarkdownIncrementalParser = class private FBuffer: string; FCursor: Integer; FContext : TParserContext; FOnMarkdownEvent: TMarkdownCallback; FElementStack : TStack<TMarkdownElementType>; FLastEvent : TMarkdownEvent; FLastEventElement : TMarkdownElementType; |
Some elements are referred to as ‘inline’: bold, italic, and inline code. Some are not, such as headings. This is used to track where they are valid.
Let’s incrementally parse:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | procedure TMarkdownIncrementalParser.ParseChunk(const Chunk: string); begin FBuffer := FBuffer + Chunk; var CursorOrig := FCursor; while (FCursor < Length(FBuffer)–1) do begin DetectElement; if FCursor <> CursorOrig then // If progressing, continue CursorOrig := FCursor else // Last iteration didn’t move the cursor, can’t parse further, quite Break; end; end; |
In short: append to the buffer. DetectElement() does the main work. If the cursor is moving, keep going and try to parse even more; if it didn’t move (ie DetectElement() or the methods it calls did not successfully parse) then stop and wait for the next chunk.
1 2 3 4 5 6 7 8 9 | procedure TMarkdownIncrementalParser.DetectElement; begin case FContext.State of psNone, psHeading, psList: BeginElementDetection; psCodeBlockStart, psCodeBlock, psInlineCode: ContinueCodeBlock; end; end; |
This checks the current state. If it’s in any form of code block, continue it (it will keep emitting code until it gets to the end backtick(s).) If it’s in a heading or list, or there is no state, try to parse.
BeginElementDetection is the monster.
Starting at the current cursor, it scans ahead to find formatting marks. These can be # for headings, * or – or + for unordered lists, * or _ for italic or bold, any number for an ordered list, or a backtick to start inline code or a code block, plus line breaks.
The closest of these to the cursor (the first one found) then decides what to do. This is all based on the current state: for example, if currently inside a heading, it does not parse for another # symbol, but it does parse for inline code, inline bold, or inline italic. Text found before the next formatting change is simply emitted as content.
This boils down to a switch statement for what kind of content to attempt to parse:
1 2 3 4 5 6 7 8 | case LookFor of lfNone, lfLineBreak: ParsePlainContent; // Can include line breaks / end sections lfCode: ParseCode(CodeStartPos); lfHeading: ParseHeading(HeadingStartPos); lfUnorderedList: ParseUnorderedList(UnorderedListPos); lfNumberedList: ParseNumberedList(NumberedListPos); lfBoldItalic: ParseBoldItalic(BoldItalicStartPos); end; |
One of the simplest to parse is headings, which begin with any number of # marks, eg # is a level 1 heading and ### is a level 3 heading:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | procedure TMarkdownIncrementalParser.ParseHeading(HeadingStartPos : Integer); begin // Any number of hashes, plus a space, indicates a heading const HeadingLevel = HasHashesFollowedBySpace(FBuffer, HeadingStartPos); if HeadingLevel = 0 then Exit; // Chunk may have sent hashes, but not a space yet assert(HeadingLevel >= 1, ‘Parsing a heading, but heading not found’); FContext.State := psHeading; FContext.ElementType := metHeading; DoEvent(FContext.ElementType, meStart, ‘h’+IntToStr(HeadingLevel)); // eg h1, h4 — could be transformed into HTML //Inc(FCursor, HeadingLevel + 1); // Number of hashes, plus space FCursor := HeadingStartPos + HeadingLevel + 1; end; |
This:
- Validates it can parse a heading. Finding # is not enough; there might be more #s coming, so we can only know the heading level once there’s whitespace.
- Updates the current state: inside a heading, and element is a heading
- Emits the event. This is key. Each event has the element type, if it starts, ends or has content, and element-specific data: for headings, it stores the heading level in HTML-like notation
- Updates the cursor indicating the last place it successfully parsed to
For Markdown like:
1 2 3 | # Heading here Hello *world*! |
This gets a sequence of events like:
- heading, start, ‘h1’
- heading, content, ‘Heading here’
- heading, end, ”
- text, start, ”
- text, content, ‘hello ‘
- italic, start, ”
- italic, content, ‘world’
- italic, end, ”
- text, start, ”
- text, content, ‘!’
- text, end, ”
And those can be used to convert to HTML or rich text.
Tests
There are far more edge cases or state to track than I had expected: Markdown is a simple format but has gotchas.
Unit tests. Unit tests. Unit tests.
It was quite common to break something while trying to add support for more complex cases. Not just writing tests ahead of time for what I was trying to get the output to be, but just a growing set of tests day after day against known working Markdown and output was extremely helpful.
The nice thing about emitting a stream of events is that unit tests can verify against a list of specific events and their data very cleanly.
Rendering Markdown
We’re almost there.
The Owl, inside Delphi, currently uses a rich text field. This is not super pleasant to code against but is mainly because the Edge browser embedding is really hard to get working and I eventually fell back to using a TRichEdit instead.
This is not ideal because it’s not as nice to work with; is much harder to get to respond to dark mode changing; and in high DPI the rich edit seems to have a bug where list marks (a dot, number, etc) may or may not draw at the right size seemingly randomly.
If you know a reliable technique to dynamically create an embedded Edge browser, ensuring it finds the right DLL, etc etc, I would be very grateful to hear about it!
I have two builder classes, THTMLBuilder and TRichTextBuilder. HTML is much nicer than RTF so for simplicity’s sake I’ll share that code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | type THTMLChangeEvent = procedure(const AFullHTML, AAppendHTML : string) of object; THTMLBuilder = class private FFullHTML : string; FOnHTMLBuild: THTMLChangeEvent; procedure AddHtml(const ANewHTML: string); public constructor Create; destructor Destroy; override; procedure AddFromMarkdown(ElementType: TMarkdownElementType; Event: TMarkdownEvent; const Text: string); property OnHTMLBuild : THTMLChangeEvent read FOnHTMLBuild write FOnHTMLBuild; end; |
It’s very simple: gets a markdown event, and adds something. This could be a tag, an end tag, or content. For example:
1 2 3 4 5 6 7 8 9 10 | case ElementType of metText: if FCurrentTag.Count = 0 then NewElem := ‘<p>’; metHeading: NewElem := ‘<‘ + Text + ‘>’; // Text is, eg, h1 or h4 metInlineCode: NewElem := ‘<code>’; metCodeBlock: NewElem := ‘<pre><code>’; metNumberedList: NewElem := ‘<ol>’; metUnorderedList: NewElem := ‘<li>’; end; FCurrentTag.Push(NewElem); AddHTML(NewElem); |
Ending a tag or just adding text is even simpler.
How many layers?
So there we have it.
- The AI server streams to the Owl server
- The Owl server parses on the fly and streams JSON to the client
- The client parses on the fly and extracts Markdown from the JSON
- The Markdown is also parsed on the fly, and emitted as a stream of events
- Those events are used to generate/build HTML or rich text
And yet it looks so simple in practice!
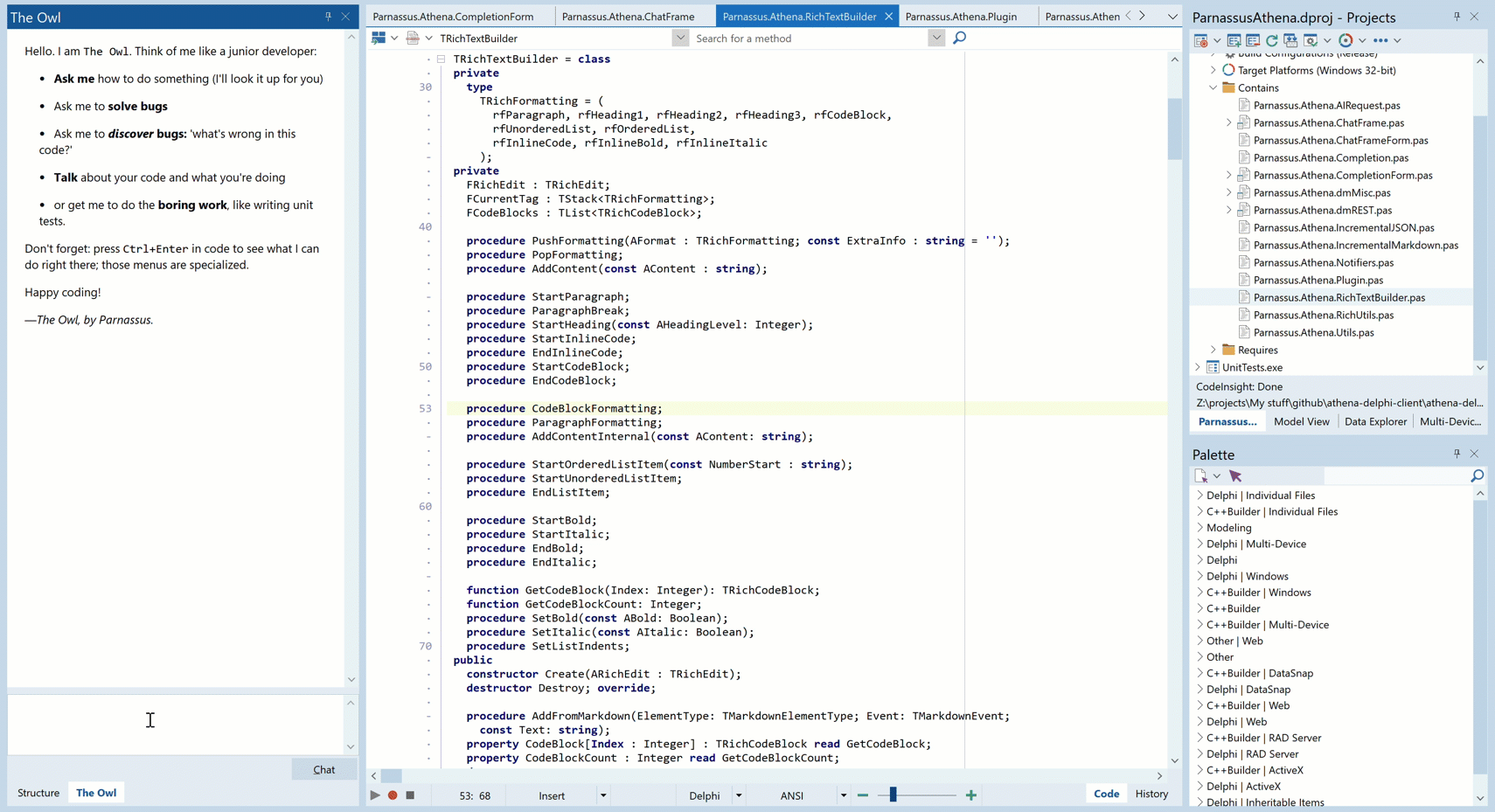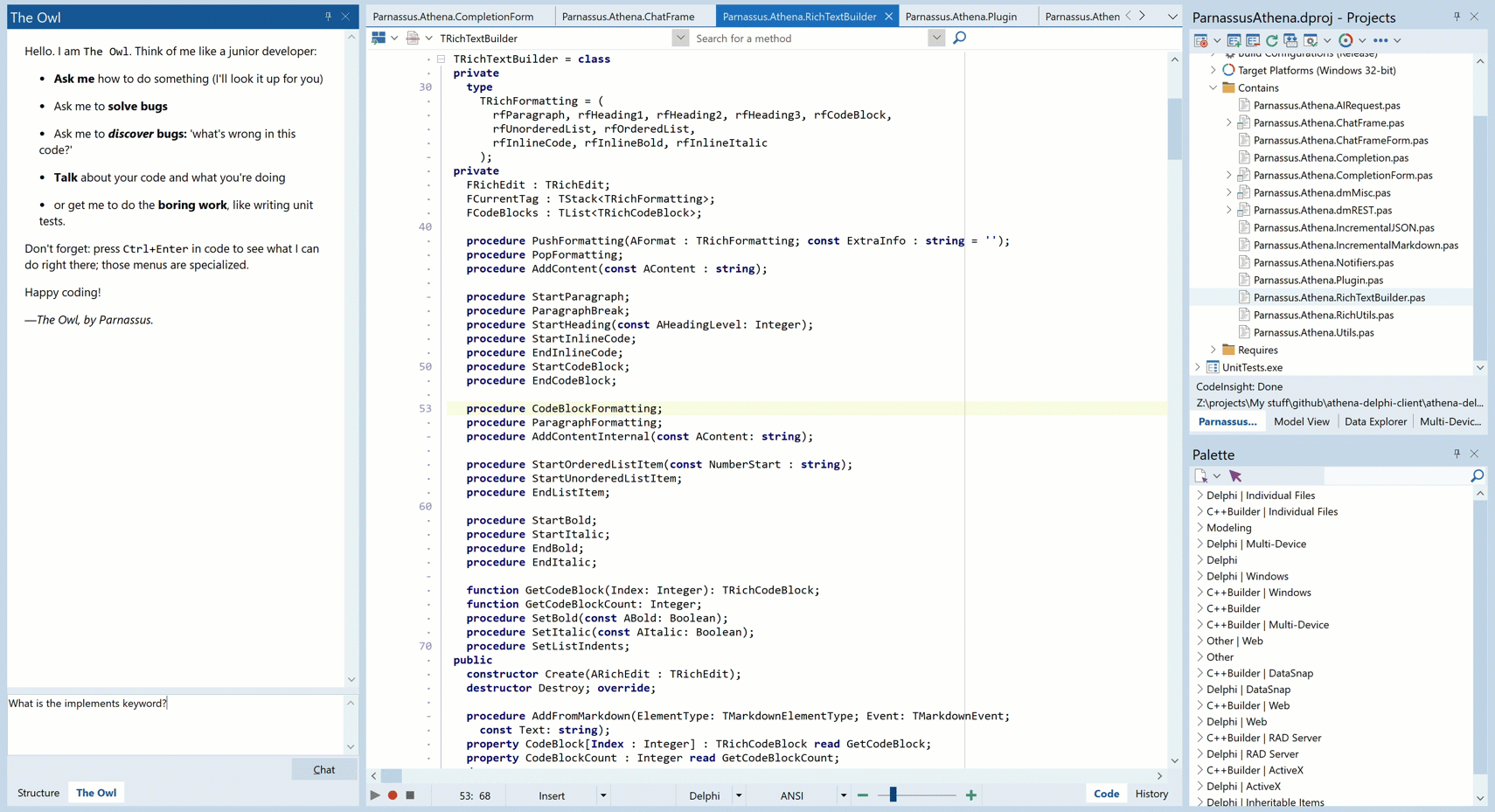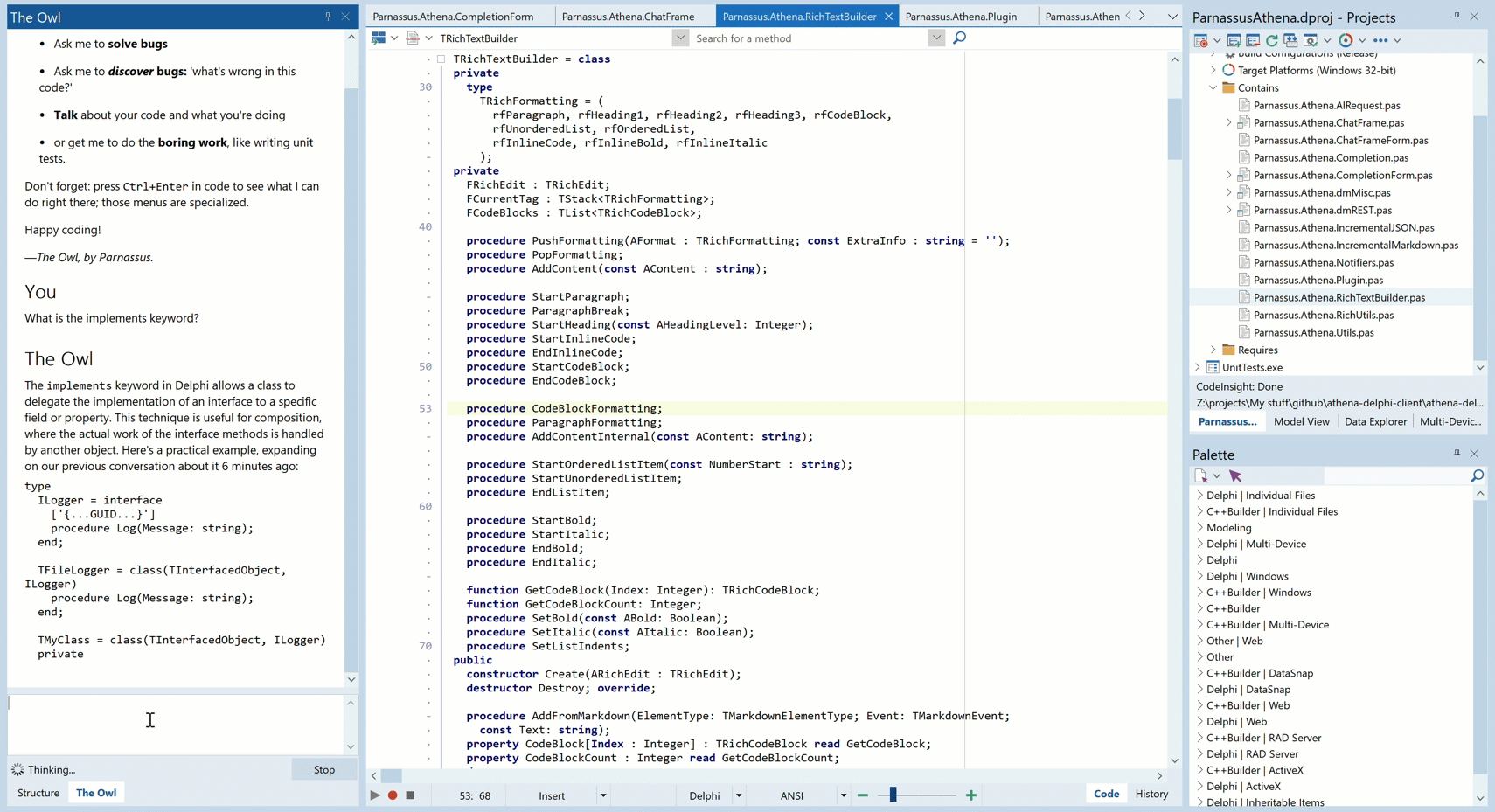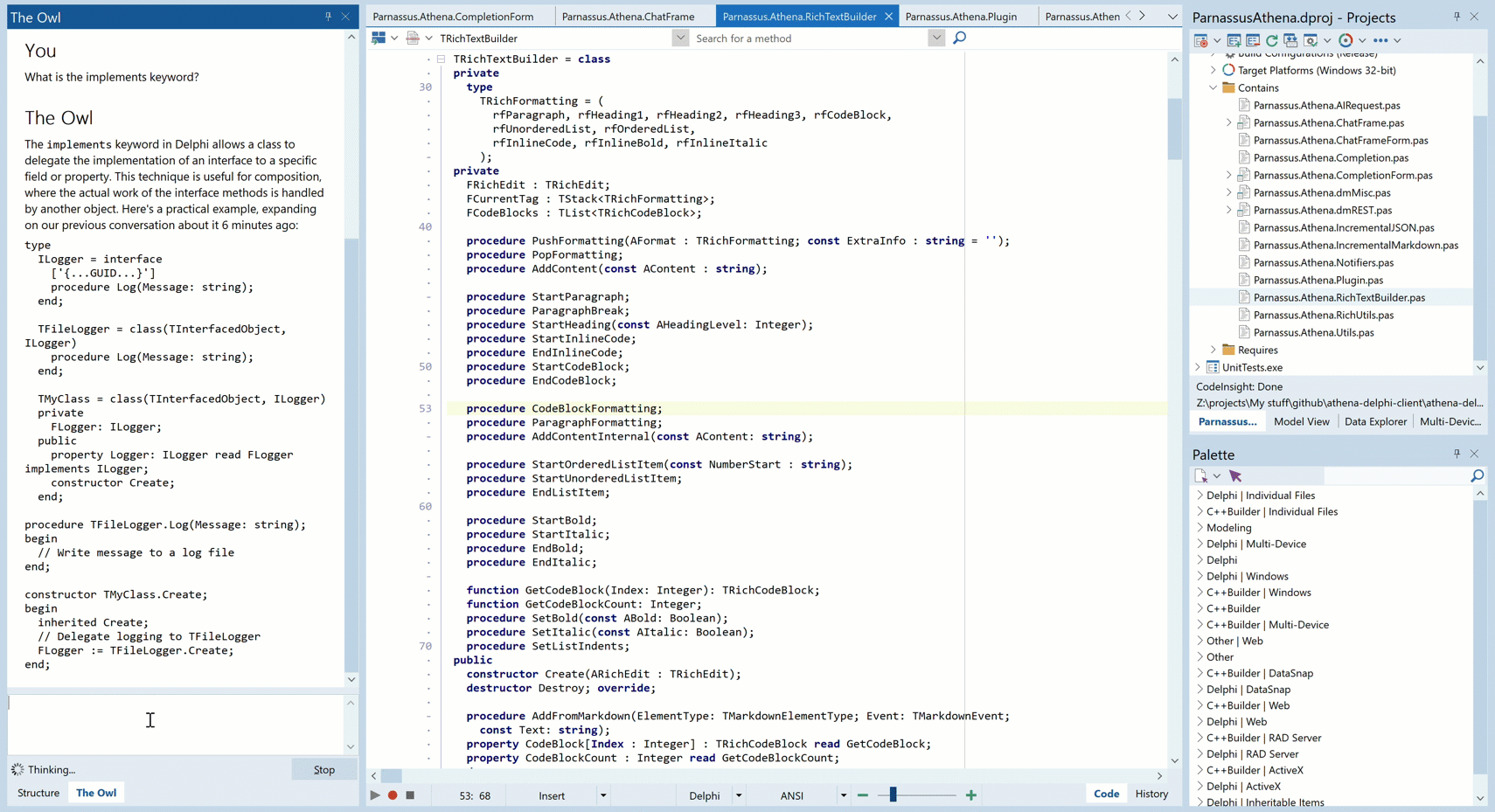
Animated GIF – you may need to click to play.
And see that note the AI says about a conversation we had six minutes before? That’s because it has a memory. More on that in another post…
And for info, this still gets us up only to March in terms of development, five months ago.
Happy coding!
Code license: in general, like most blogs, code is for information and education. There’s no error checking, and it’s not suitable for product. Also, don’t use this to create anything competitive to the Owl, ie an AI service or copilot targeting Delphi/C++Builder.
If you do want to use it for some kind of copilot for RAD Studio, drop me an email (I’ll likely say yes, just don’t want surprises.) I prefer working with people :)
And on that note if you want to build an AI service, get in touch!
Leave a Reply